
主从复制
在最基础的Redis应用中,可能只有一个Redis实例,这种模式简单直接,但存在明显的风险:一旦实例宕机,所有依赖它的服务都会收到影响,并且数据可能丢失.为了解决这个问题,Redis引入了主从复制(Master-Slave Relication)
定义
主从复制允许我们将一台 Redis 服务器(Master 主节点)的数据完整地、实时地复制到一台或多台其他的 Redis 服务器(Replica 从节点,旧称 Slave)。
- Master (主节点): 负责处理客户端的写操作,并将数据变更同步给所有连接的从节点。它也可以处理读操作。
- Replica (从节点): 通常配置为只读,从主节点接收数据更新。它可以处理客户端的读操作,从而分担主节点的读压力。
为什么使用主从复制
-
数据冗余: 数据在多个节点上存在副本,即使主节点发生故障,数据依然存在于从节点,为数据恢复提供了保障。
-
读写分离/读扩展: 将读请求分散到多个从节点,降低主节点的负载压力,提高应用的整体读性能。主节点可以更专注于处理写请求。
-
数据备份: 可以在从节点上执行数据备份操作(如
BGSAVE),避免对主节点服务性能造成影响。
主从复制如何工作
-
连接建立与同步: 从节点连接到主节点,发送同步请求 (
PSYNC)。 -
全量复制: 如果是首次连接或无法进行部分复制,主节点会生成RDB快照发送给从节点,从节点加载RDB并接收后续的增量命令。
-
部分复制: 如果从节点之前连接过且满足条件(
run_id相同,offset在复制积压缓冲区内),主节点只会发送断连期间缺失的命令。- master通过一个环形的**复制积压缓冲区(repl_backlog_buffer)**来记录从生产RDB文件开始收到的所有写命令来找到slave缺少的数据从而避免全量复制.一个master中只有一个复制积压缓冲区,master所有的slave共用
- Real_backlog_buffer是一个固定长度的队列(FIFO,先进先出),默认大小为1MB,支持自定义大小
-
命令持续传播: 同步完成后,主节点会将所有新的写命令实时异步地发送给从节点。
-
心跳与ACK: 主从节点间通过 PING/ACK 机制维持连接并监控同步状态。
PSYNC的演进
SYNC(Redis < 2.8):
- 这是最早的复制命令。
- 无论什么情况(初次连接、断线重连),都触发全量复制。效率低下。
PSYNC(或称PSYNC1, Redis 2.8 - 3.x):
- 引入了部分重同步 (Partial Resynchronization) 的概念。
- 核心依赖三个要素:
- 主节点的运行ID (
run_id或master_replid): 一个随机字符串,主节点启动时生成。从节点会记录其主节点的run_id。 - 复制偏移量 (offset): 主从双方都维护一个偏移量,表示已发送/已接收的复制流的字节数。
- 复制积压缓冲区 (replication backlog): 主节点上一个固定大小的循环缓冲区,存储最近发送的写命令。
- 主节点的运行ID (
- 工作流程:
- 从节点连接主节点时,发送
PSYNC <master_run_id> <offset>。 - 主节点检查:
- 如果
master_run_id与自身的run_id匹配,并且offset之后的数据仍在积压缓冲区内,则执行部分重同步,只发送缺失的数据。 - 否则,执行全量重同步 (
+FULLRESYNC <new_run_id> <current_offset>)。
- 如果
- 从节点连接主节点时,发送
PSYNC1的不足:- 如果主节点崩溃并重启,它的
run_id会改变。即使数据可能大部分还在(通过持久化恢复),所有从节点也必须进行全量重同步。 - 如果发生故障转移,一个从节点被提升为新的主节点,它的
run_id与旧主节点不同。其他从节点连接到这个新主节点时,因为run_id不匹配,也必须进行全量重同步,即使新主节点的数据与它们之前复制的旧主节点数据有很大重叠。
- 如果主节点崩溃并重启,它的
PSYNC2(Redis 4.0+):
PSYNC2 的目标就是优化上述 PSYNC1 在故障转移场景下的不足,使得在主节点角色发生变化后,从节点仍有更大机会进行部分重同步。
- 保留了
replid(原run_id) 和offset:- 每个 Redis 实例(无论是主还是从)都有一个主复制ID (
replid)。当一个实例成为主节点时,这个replid标识了它所生成的数据流的历史。从节点会继承其主节点的replid。 offset仍然是这个replid历史中的字节偏移量。
- 每个 Redis 实例(无论是主还是从)都有一个主复制ID (
- 引入了
replid2和second_repl_offset:- 每个主节点现在还维护第二个复制ID (
replid2) 和第二个复制偏移量 (second_repl_offset)。 replid2的作用: 当一个从节点被提升为新的主节点时(例如通过 Sentinel 或 Cluster 的故障转移),这个新的主节点会将其之前作为从节点时所复制的旧主节点的replid存储在自己的replid2中。同时,它也会记录一个second_repl_offset,表示它从旧主节点那里复制到的偏移量。- 故障转移后的部分重同步:
- 假设 MasterA (replid=A, offset=X) 宕机。
- SlaveB (之前复制 MasterA,所以它也知道 replid=A 和自己同步到的 offset_B) 被提升为 NewMasterB。
- NewMasterB 会生成一个新的自己的
replid(例如 replid=B),但它会把旧主节点A的replid(即A) 存到自己的replid2中,并记录它从A同步到的偏移量offset_B作为second_repl_offset。 - 现在,另一个从节点 SlaveC (之前也复制 MasterA,知道 replid=A 和自己同步到的 offset_C) 尝试连接到 NewMasterB。
- SlaveC 发送
PSYNC A offset_C。 - NewMasterB 收到后,会检查:
- SlaveC 请求的
replid(A) 是否与自己的主replid(B) 匹配or不匹配。 - 关键:SlaveC 请求的
replid(A) 是否与自己的第二个replid(replid2) (即A) 匹配or匹配! - 如果匹配,并且 SlaveC 请求的
offset_C在 NewMasterB 的second_repl_offset(即offset_B) 范围内,并且 NewMasterB 的复制积压缓冲区中包含了从offset_C到offset_B这段属于旧主节点A历史的命令,那么就可以进行部分重同步。NewMasterB 会先发送这部分属于旧主节点历史的命令,然后再发送自己成为主节点后产生的新命令
- SlaveC 请求的
- 每个主节点现在还维护第二个复制ID (
为什么主从全量复制使用RDB而不是AOF
- RDB文件存储的内容是经过压缩的二进制数据,文件很小.而AOF文件存储的是每一次写命令,类似于MySQL的binlog日志,通常会比RDB文件大很多.因此,传输RDB文件更节省带宽,速度也更快
- 使用RDB文件恢复数据,直接解析还原数据即可,不需要一条一条地执行命令,速度非常快,而AOF则需要依次执行每个写命令,速度非常慢.也就是说,在恢复大数据集的时候,RDB的速度要更快
- AOF需要选择合适的刷盘策略,如果刷盘策略选择不当的话,会影响Redis的正常运行.并且,根据所使用的刷盘策略,AOF的速度可能会慢于RDB
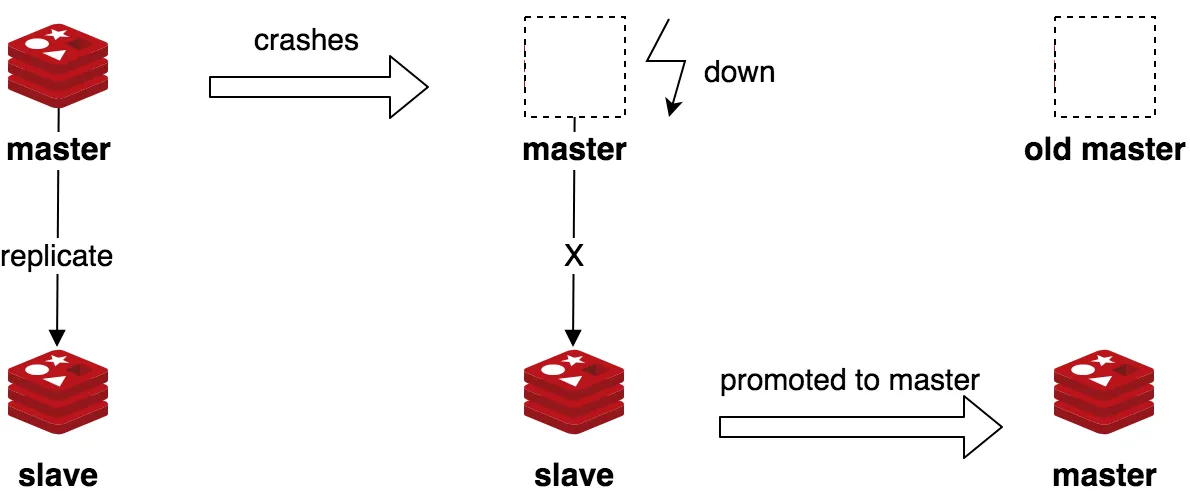
局限性
虽然主从复制提供了数据冗余,但它本身并不具备自动故障转移的能力。如果主节点宕机,需要人工介入,选择一个从节点提升为新的主节点,并修改其他从节点和客户端的配置。这个过程既不及时也容易出错。
为了解决这个问题,我们需要一个更加高效的工具——Redis Sentinel
评论区
请登录后发表评论